研究背景
目前强大的语言模型普遍在很多下游 NLP 任务中能轻易地达到比较好的结果,但在推理效果上没有达到预期。字节跳动人工智能实验室与新加坡科技与设计大学提出一个基于演绎推理的方法,希望实现类似 System 2 的推理能力。

研究动机
作为一类需要解题的推理过程,在数学解题任务中比较适合应用演绎推理模型。研究团队尝试在此任务上做一些多步的推理 (multi-step reasoning), 使得模型预测能够提供相对可解释的预测结果。
问题描述
在给定一个数学问题的情况下,研究团队进行算术解答并得到答案。
Question: In a division sum , the remainder is 8 and the divisor is 6 times the quotient and is obtained by adding 3 to the thrice of the remainder. What is the dividend?
Answer: 129.5
Mathematical Expression: ((8×3+3)×(8×3+3)÷6)+8
上面的这个(取自于 MathQA [3] dataset)例子中,研究团队需要得到最后被除数 (dividend) 129.5。同时数据集也给出计算的表达式,可以用来当作监督信号。这种多步的表达式,也便于验证 multi-step reasoning 的方法。这边研究团队也主要考虑一些基本的数学运算符,包括加 (+) 减 (-) 乘 (×) 除 (÷) 以及幂 (^),其他更复杂的运算其实可以分解成这些基本的运算。
现有方法
目前流行的数学解题方法主要是 sequence-to-sequence (Seq2Seq) 以及 sequence-to-tree (Seq2Tree) 的方法。针对 Seq2Seq 的方法,优点是简单直接,缺点是需要有非常大量的数据才得到好的效果,否则效果不如结构化模型 Seq2Tree。Seq2Tree 主要的代表工作是 Goal-Driven Tree-Structure (GTS) [4],目前也是大家比较频繁借鉴的工作。同时 Seq2Tree 也有可以改进的地方,如下图所示,生成的过程是一个前序遍历 (pre-order traveral) 的过程,会先生成顶端的数学运算符 (operator),然后是 operator 左边的运算,最后是右边的运算。生成的过程相对来说比较不符合直觉,并不是一个一步步计算的过程。此外,可以看到同一个表达式 8×3+3 被生成了 2 次,然而其实是可以重复使用这个表达式的结果。但在 Seq2Tree 的方法中,无法这样去使用,必须重新生成整个子树结构。
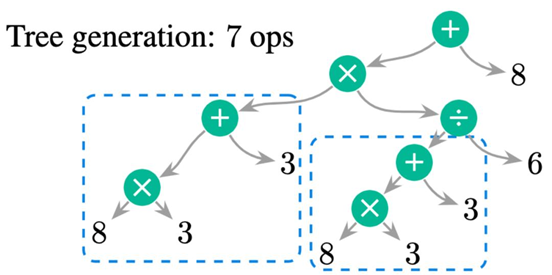
研究过程
研究团队的思路其实比较直接,通过一步步的方法得到最后的结果,并且每一步的生成可以对应到文中相应的描述。

如上图所示,只需要对所提供的表达式拆成多步运算即可。前两步的运算,得到除数 divisor,第三步得到商 quotient ,最后两步则得到最后的被除数 dividend。对于每一步,都能够找到文中相对应的文本描述,总的来说,有以下的优点:
通过重复利用已有的结果计算,减少了总的计算步数。
一步步的计算过程相对于 Seq2Tree 的生成更加可解释。
生成是生成整个表达式,而不是单个 operator 或者是数字。这样的 constraint 在训练过程中使得模型要更加准确的得到整个表达式。
额外的一个优点是,假如已经有了前三步,也可以从第三步出发继续推理,不需要从头开始。
推理系统
模型输入:在问题中出现的数字以及整个 constant 的集合,用 Q 表示。
对于表达式的表示:
表示从 q_i 到 q_j 的数学运算,上述这个表达式
是有方向性的。比如对于减法或者除法,会有「-_reverse」这样的符号,代表相反的方向 q_j - q_i。
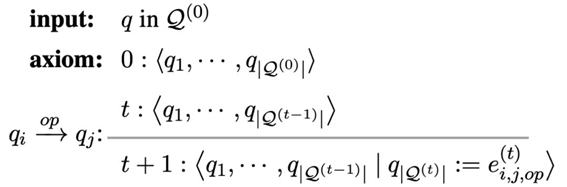
从正式的演绎推理系统角度,可以用上图表示状态的变化 (和 Dependency Parsing 中的 transition-based system 类似),从 t 到 t+1 状态的变化主要是增加了新的表达式,并且这个新的表达式会成为新的候选数字加入到下一个状态当中。
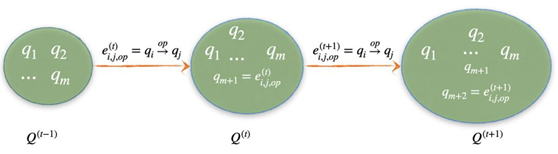
上面这张图简单地可视化了状态的变化过程也可以看到,随着 t 的增加,状态的 size 也会由于新的数字的加入随之变「大」。
模型实现
首先还是用预训练语言模型例如 BERT 或者 Roberta 得到数字的向量表达 (representation),然后在这个基础上做 inference。这边用一个 q_1/q_2 × q_3 作为例子:
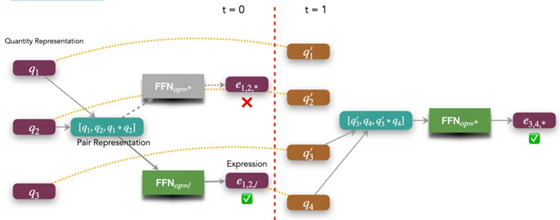
第一步得到 q_1 和 q_3 的联合表示,主要通过拼接 representation 方式完成,然后对于每一个 operator ,有一个 operator-specific 的 Feed-forward network 来得到数学表达式 e_{1,2,÷} 的向量表达,从而这个新的表达式在下一个 timestep,会变成新的候选数字 q_4。同时,在 inference 的过程当中,可能会得到错误的表达式,比如说上图的 e_{1,2,×}。所以,是在所有可能的表达式中,通过 scoring 选取一个最好的表达式来当作 q_4。然后当 t=1 的时候,最后能得到 e_{3,4,×} = q_3 × q_4。
注意到的是,在不同的 timestep t,状态当中数字数量不同,导致所有可能的数学表达式的数量不同。如果做 beam-search 的话,这种情况是比较困难的。因为每个 timestep 的概率分布会不平衡。
这种方法的好处是可以增加一些 constraints,比如说如果 e_{1,2,×} 是一个不可能出现的表达式,或者是 q_1× q_2 的结果是不可能存在的,则可以直接从整个状态空间中去掉这个表达式。
实验
研究团队主要在现有的公开数据集中做实验:MAWPS, Math23k, MathQA 和 SVAMP。这边展示一些现有比较好的方法的主要结果。实验过程中,最好的 varaint 是 「Roberta-DeductiveReasoner」,并且不采用 beam-search,这边比较的之前的工作,全都有采用 beam size 为 5 的 beam search。
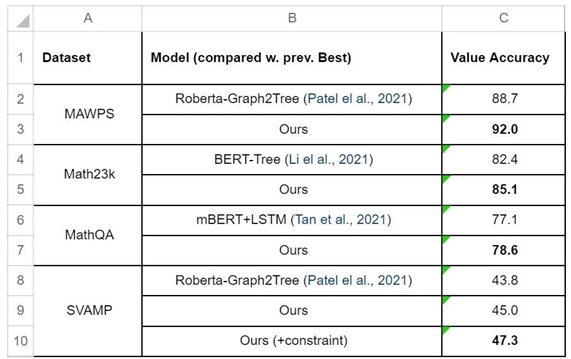
整体来说,在答案的准确率上能比之前的 seq2tree 的工作都高出不少,把主要的提升归咎于预测整个表达式,而不是一个个操作符和数字。但整体的绝对数字,发现并不高,尤其是 SVAMP ,文章中后续对 SVAMP 的困难度做了一些分析,详细可以看一下文章细节。对于 SVAMP 数据集,研究团队发现 constraint 的作用尤其大,这里的 constraint 主要是不允许中间结果出现负数。这个 constraint 对于BERT-based 的 Reasoner 能提高 7 个点的准确率,对于 Roberta-based 的 Reasoner 能提高 2 个点。
可解释分析
在这个例子中,想展示模型的可解释的能力。
Question: There are 255 apple trees in the orchard. Planting another 35 pear trees makes the number exactly the same as the apple trees. If every 20 pear trees are planted in a row, how many rows can be planted in total?
Answer: 11. Gold Expression: (255 - 35) / 20. Predicted Expression: (255 + 35) / 20 Deductive Scores: Prob(‘255+35=290’) = 0.068 > Prob(‘255-35=220’) = 0.062
模型在第一步表达式预测错误,定位到图中标红的那一句描述。研究团队怀疑「planting another」会误导模型去预测 + 的数学运算符。通过修改那一句话希望那一句话会有更准确的表达,下图中标蓝的为修改后的话。
Question: There are 255 apple trees in the orchard. The number of pear trees is 35 fewer than the apple trees. If every 20 pear trees are planted in a row, how many rows can be planted in total?
Prob(255+35=290) = 0.061 < Prob(255-35=220) = 0.067
通过 fewer 这个词希望让模型知道这个地方是一个减法。这个分析能让我们从模型的预测中,学习到模型 inference 过程中的一些行为。
研究价值
本文提出的整体演绎推理系统从速度上相对树结构模型更高效,并且可以提供一些可解释的解答步骤。此外,也能加入一些先验知识变成 constraint ,从而提高模型的效果。从理论上说,研究团队的演绎推理模型可以不仅仅用在数学解题上,对于其他涉及多步推理的问答任务以及一些结构预测任务也是适用的。
该模型也有一些缺陷,比如说计算中有很多的数学运算符以及常数的时候,模型耗费的空间会比较大,造成资源的浪费。此外,beam search 目前还无法很好的地运用在这个框架下面,会有上文提到的概率分布不平衡的问题。
智能推荐
创新利用蓝宝石纤维制备传感器
2022-08-09牛津大学的研究人员开发了一种由蓝宝石纤维制成的传感器,该传感器可以承受极端温度,有望显著提高航空航天和发电领域的效率和减排。
涉及学科涉及领域研究方向发育生物学创新 | 重建“细胞框架”以探究胚胎发育的复杂过程
2022-11-23使用高级数学建模,创建来自众多生物体的细胞类型的详细图谱,探究“原肠胚”的发育过程,精准跟踪细胞的发育和分化。
涉及学科涉及领域研究方向前沿医学 | 通过分析交通事故数据帮助预测车祸受害者的脑损伤风险
2022-08-31帝国理工大学的研究人员在这项研究者确定了速度、方向和头部保护水平如何预测道路交通碰撞(RTC)后的脑损伤。这些发现为自动识别最可能导致脑外伤的碰撞提供了数据。这可以为现有的碰撞通知系统提供基础,以便更好地预测严重伤害的风险,并向紧急服务部门通报。这可以帮助急救人员确保患者迅速得到最适当的治疗。
涉及学科涉及领域研究方向利用图神经网络建立可解答大学水平难题的机器学习模型
2022-08-15研究团队使用神经网络建立了一个机器学习模型。他们利用程序合成和少镜头学习的技术将本科数学课程中的问题转化为编程任务,然后使用对文本进行预训练的神经网络对代码进行了“微调”,并适当地添加关于问题的“备注”。实验结果表明,该模型对大学水平的数学问题解答的准确率高达80%以上,并能够生成新的问题。这项工作可以用来简化课程内容的生成,这在有数千名学生的大型住校课程和大规模开放在线课程(mooc)中尤其有用。该系统还可以用作自动化导师,向学生展示本科数学问题的解题步骤,为人们打开了利用机器学习解答难题的新领域。
涉及学科涉及领域研究方向